Particle Filters and Ghost Tracking
Bayesian inference for tracking invisible ghosts in Pacman. Exact inference with the forward algorithm, particle filters, and joint tracking of multiple ghosts.
Abstract#
Fourth and final Pacman assignment. Pacman can’t see the ghosts directly. He gets noisy distance readings and has to infer where they are using probabilistic inference. The assignment goes from exact Bayesian inference to particle filters, then scales up to tracking multiple ghosts jointly with a joint particle filter. The math is Bayes’ rule and the forward algorithm, but the implementation has some fiddly edge cases around captured ghosts and zero-weight particles that took me a while to get right.
This is the Ghostbusters variant of Pacman. The ghosts are invisible, but Pacman gets noisy distance observations at each timestep. You build inference modules in inference.py that maintain belief distributions over ghost positions, and then a simple agent in bustersAgents.py uses those beliefs to chase ghosts.
All code is Python 2, variable names as-is.
Exact inference: observation update#
The belief distribution is a probability distribution over the ghost’s position. When Pacman receives a noisy distance reading, it updates the belief using Bayes’ rule:
The emission model is provided by the framework. You multiply the prior by the likelihood and normalize.
def observe(self, observation, gameState):
noisyDistance = observation
emissionModel = busters.getObservationDistribution(noisyDistance)
pacmanPosition = gameState.getPacmanPosition()
allPossible = util.Counter()
for p in self.legalPositions:
trueDistance = util.manhattanDistance(p, pacmanPosition)
allPossible[p]=self.beliefs[p]*emissionModel[trueDistance]
if noisyDistance==None:
allPossible[self.getJailPosition()]=1.0
allPossible.normalize()
self.beliefs = allPossibleThe noisyDistance == None case handles a captured ghost. When a ghost is eaten, the noisy distance is None and the ghost goes to jail. All belief concentrates at the jail position.
The jail check is inside the loop, so it gets set on every iteration. It should be outside the loop (or in an if/else wrapping the whole thing), but it works because the last assignment to the jail key is the one that sticks, and after normalization the jail position gets probability 1.
Exact inference: time elapse#
Between observations, the ghost moves. The time-elapse step uses the forward algorithm to propagate beliefs through the transition model:
For each old position with nonzero belief, you compute where the ghost could move to and spread the probability accordingly.
def elapseTime(self, gameState):
updatedBeliefs=util.Counter()
for position,probability in self.beliefs.iteritems():
if probability:
self.setGhostPosition(gameState, position)
ghostPostDistribution = self.getPositionDistribution(gameState)
for position1 in self.legalPositions:
updatedBeliefs[position1]+=probability*ghostPostDistribution[position1]
updatedBeliefs.normalize()
self.beliefs = updatedBeliefsself.setGhostPosition(gameState, position) modifies the game state to place the ghost at position, then self.getPositionDistribution(gameState) returns the distribution over where the ghost moves next from that position. The if probability: check skips positions with zero belief, which is a performance optimization.
The double loop (over old positions and new positions) is the marginalization. You accumulate B(old) * P(new | old) for each pair.
Particle filter: initialization#
Exact inference tracks a probability for every legal position. A particle filter approximates the distribution with a set of samples (particles). Each particle is a position where the ghost might be.
def initializeUniformly(self, gameState):
self.particles=[]
tempLegalPositions=self.legalPositions
particleCount=0
while particleCount<self.numParticles:
for position in tempLegalPositions:
if particleCount<self.numParticles:
self.particles.append(position)
particleCount+=1This distributes particles round-robin across legal positions. If you have 100 particles and 25 legal positions, each position gets exactly 4. If the numbers don’t divide evenly, some positions get one extra.
Particle filter: observation update#
When an observation comes in, you re-weight particles by the emission model and resample:
def observe(self, observation, gameState):
noisyDistance = observation
emissionModel = busters.getObservationDistribution(noisyDistance)
pacmanPosition = gameState.getPacmanPosition()
if noisyDistance==None:
for particleCounter in range(self.numParticles):
self.particles[particleCounter]=self.getJailPosition()
else:
currentBeliefDistribution = self.getBeliefDistribution()
newBeliefDistribution=util.Counter()
for position in self.legalPositions:
distance=util.manhattanDistance(position,pacmanPosition)
if emissionModel[distance]>0:
newBeliefDistribution[position]=emissionModel[distance]* currentBeliefDistribution[position]
if newBeliefDistribution.totalCount()==0:
self.initializeUniformly(gameState)
else:
for particleCounter in range(self.numParticles):
self.particles[particleCounter]=util.sample(newBeliefDistribution)Three cases:
- Ghost captured: all particles go to jail.
- All particles get zero weight (none of the current particles are consistent with the observation): reinitialize uniformly and start over.
- Normal case: convert particles to a distribution, weight each position by the emission probability, resample all particles from the weighted distribution.
The getBeliefDistribution method just counts particles and normalizes:
def getBeliefDistribution(self):
beliefDistribution=util.Counter()
for particle in self.particles:
beliefDistribution[particle]+=1.0
for particle in beliefDistribution:
beliefDistribution[particle] /= self.numParticles
return beliefDistributionParticle filter: time elapse#
For the time step, each particle is independently moved by sampling from the transition model:
def elapseTime(self, gameState):
tempParticles=[]
for particle in self.particles:
newPosDist = self.getPositionDistribution(self.setGhostPosition(gameState, particle))
tempParticles.append(util.sample(newPosDist))
self.particles=tempParticlesFor each particle, you set the ghost to that position, get the distribution over next positions, and sample one. The new sample replaces the old particle. This is simpler than the exact inference version because you don’t have to do the full marginalization. You just sample.
Joint particle filter#
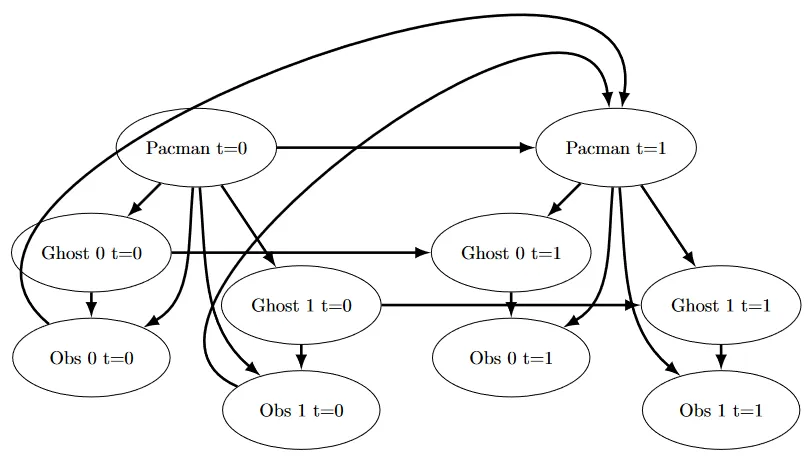
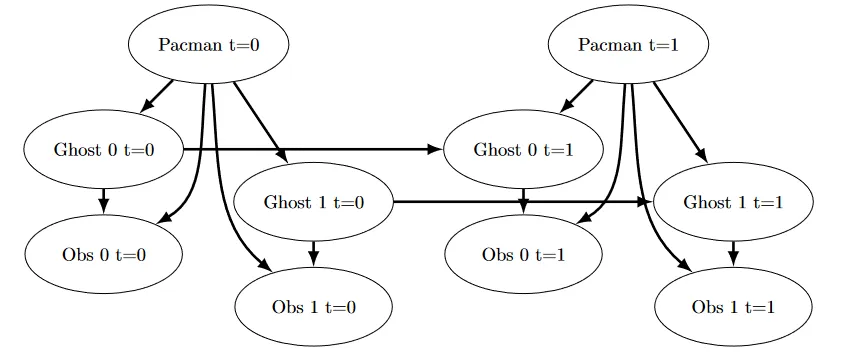
With multiple ghosts, the state space is the Cartesian product of all ghost positions. If there are 2 ghosts and 100 legal positions, that’s 10,000 possible states. With 3 ghosts it’s 1,000,000. Exact inference doesn’t scale, so you use a joint particle filter where each particle is a tuple of positions (one per ghost).
Initialization builds the full Cartesian product, shuffles it, and distributes particles round-robin:
def initializeParticles(self):
tempLegalPositions= list(itertools.product(self.legalPositions, repeat = self.numGhosts))
random.shuffle(tempLegalPositions)
particleCount=0
self.particles=[]
while particleCount<self.numParticles:
for position in tempLegalPositions:
if particleCount<self.numParticles:
self.particles.append(position)
particleCount+=1The shuffle is important. Without it, particles would be biased toward the first entries of the Cartesian product (positions with low coordinates).
Joint observation update#
The observation update re-weights particles by the emission probability of each ghost independently:
def observeState(self, gameState):
pacmanPosition = gameState.getPacmanPosition()
noisyDistances = gameState.getNoisyGhostDistances()
if len(noisyDistances) < self.numGhosts:
return
emissionModels = [busters.getObservationDistribution(dist) for dist in noisyDistances]
beliefDistribution = self.getBeliefDistribution()
for ghostIndex in range(self.numGhosts):
if noisyDistances[ghostIndex] == None:
for particleCounter in range(self.numParticles):
self.particles[particleCounter] = self.getParticleWithGhostInJail(self.particles[particleCounter], ghostIndex)
beliefDistribution = self.getBeliefDistribution()
else:
for particle in beliefDistribution:
distance = util.manhattanDistance(particle[ghostIndex], pacmanPosition)
beliefDistribution[particle] = beliefDistribution[particle] * emissionModels[ghostIndex][distance]
if beliefDistribution.totalCount()==0:
self.initializeParticles()
for particleCounter in range(self.numParticles):
for ghostIndex in range(self.numGhosts):
if noisyDistances[ghostIndex] == None:
self.particles[particleCounter] = self.getParticleWithGhostInJail(self.particles[particleCounter], ghostIndex)
else:
beliefDistribution.normalize()
tempParticles=[]
for particleCounter in range(self.numParticles):
tempParticles.append(util.sample(beliefDistribution))
self.particles=tempParticlesThis is the most complex function in the assignment. It processes each ghost in sequence:
- If a ghost is captured, update all particles to put that ghost in jail and recompute the distribution.
- If a ghost is alive, multiply each particle’s weight by that ghost’s emission probability. The multiplication happens across all ghosts on the same distribution, so the final weight is the product of all ghost likelihoods.
The zero-weight recovery path reinitializes particles and then fixes up any jailed ghosts. The double loop at the end (for particleCounter ... for ghostIndex ...) makes sure captured ghosts stay in jail even after reinitialization.
Joint time elapse#
def elapseTime(self, gameState):
newParticles = []
for oldParticle in self.particles:
newParticle = list(oldParticle)
for ghostIndex in range(self.numGhosts):
newPosDist = getPositionDistributionForGhost(setGhostPositions(gameState, newParticle),
ghostIndex, self.ghostAgents[ghostIndex])
newParticle[ghostIndex] = util.sample(newPosDist)
newParticles.append(tuple(newParticle))
self.particles = newParticlesEach ghost is sampled sequentially within a particle. Ghost 0 is sampled first, and its new position is written into newParticle before ghost 1’s transition is computed. So ghost 1’s transition is conditioned on ghost 0’s new position, not its old one. This sequential sampling captures dependencies between ghosts (they can’t occupy the same cell, for example).
The greedy agent#
With the inference module tracking ghost beliefs, the agent just chases the most likely ghost:
def chooseAction(self, gameState):
pacmanPosition = gameState.getPacmanPosition()
legal = [a for a in gameState.getLegalPacmanActions()]
livingGhosts = gameState.getLivingGhosts()
livingGhostPositionDistributions = \
[beliefs for i, beliefs in enumerate(self.ghostBeliefs)
if livingGhosts[i+1]]
mostLikelyPositionOfLivingGhosts = []
for positionDistributionOfGhost in livingGhostPositionDistributions:
maxBelief= -1*float('inf')
for position,probability in positionDistributionOfGhost.iteritems():
if probability> maxBelief:
maxBelief = probability
maxPosition = position
if maxBelief >= 0:
mostLikelyPositionOfLivingGhosts.append(maxPosition)
closestGhostPosition=mostLikelyPositionOfLivingGhosts[0]
closestGhostDistance=self.distancer.getDistance(pacmanPosition, closestGhostPosition)
for position in mostLikelyPositionOfLivingGhosts:
tempDist=self.distancer.getDistance(pacmanPosition, position)
if tempDist<closestGhostDistance:
closestGhostPosition=position
closestGhostDistance=tempDist
actions = [(self.distancer.getDistance(Actions.getSuccessor(pacmanPosition, action), closestGhostPosition), action) for action in legal]
minimumDistance = min(actions)[0]
goodActions = [action[1] for action in actions if action[0] == minimumDistance]
return goodActions[0]Three steps:
- For each living ghost, find the position with the highest belief probability (argmax over the distribution).
- Among those most-likely positions, find which ghost is closest to Pacman using true maze distance.
- Pick the legal action that moves Pacman closest to that ghost.
The distance computation uses self.distancer.getDistance, which returns the true shortest path through the maze (not Manhattan distance). The action selection builds (distance, action) tuples and takes the one with the minimum distance.
This is a greedy agent. It always chases the nearest ghost and doesn’t plan ahead. It works well when the inference module is accurate, which it is once the particle filter has had a few timesteps to converge.